
The Resource Description Framework, or RDF, is a standard model for data interchange that allows structured and semi-structured data to be shared across different applications. RDF expresses relationships between entities as triples; essentially a graph that links unique URIs via edges that describe their relationships. In this post, we’ll use the Python library rdflib to build a graph from RDF data about products and to extract information about individual products.
About the Data
The data used in this post can be found here. It comes from the Web Data Commons project, which extracts structured data describing products, people, organizations, places, and events from the Web and make the extracted data available for download. In particular, we will be exploring the subset of the corpus that concerns products and product descriptions.
import os
import requests
base_folder = "data"
products_url = "http://data.dws.informatik.uni-mannheim.de/structureddata/2014-12/quads/ClassSpecificQuads/schemaorgProduct.nq.sample.txt"
product_path = "products.nq"
def download_data(dir_path, data_url, data_path):
"""
Convenience function that uses the requests library to retrieve data
given a url to the dataset and a directory folder on your computer.
"""
if not os.path.exists(dir_path):
os.mkdir(dir_path)
response = requests.get(data_url)
with open(os.path.join(dir_path, data_path), "wb") as f:
f.write(response.content)
return data_path
download_data(base_folder, products_url, product_path)
What is RDF?
The product data we’ll be exploring is represented in RDF (Resource Description Framework) format. RDF is a directed, labeled graph data format for representing information in the Web. Resources are represented as nodes in the graph and identified by unique URIs. Edges represent the named link between two given resources.
What are N-Quads?
RDF is an abstract model with several serialization formats that have different encodings. The variant we’ll be dealing with is called N-Quad. N-Quads is a line-based, plain text format for encoding an RDF dataset. In the data we’ll be looking at, the forth element of each line contains the URL of the webpage from which the data was extracted.
Let’s take a look at the first couple lines of the raw file:
with open(os.path.join(base_folder, product_path), "rb") as input_data:
for i in range(5):
print(input_data.readline())
print("")
b'_:nodee130f8cb43e689a9fee53a44337 <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://schema.org/Offer> <http://24h.pchome.com.tw/prod/DGBO6L-A72119703> .\n'
b'_:nodedce6998dc1a66ec67558dfb368cc3e3 <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://schema.org/Product> <http://24h.pchome.com.tw/prod/DGBO6L-A72119703> .\n'
b'_:nodedce6998dc1a66ec67558dfb368cc3e3 <http://schema.org/Product/offers> _:nodee130f8cb43e689a9fee53a44337 <http://24h.pchome.com.tw/prod/DGBO6L-A72119703> .\n'
b'_:noded8ceb1a23d14863c1ee9bf9ea0ac4b90 <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://schema.org/Product> <http://800ceoread.com/products/big-wave-surfing-kenneth-j-thurber-english> .\n'
b'_:noded8ceb1a23d14863c1ee9bf9ea0ac4b90 <http://schema.org/Product/name> "\\n \\n Big Wave Surfing: Extreme Technology Development, Management, Marketing & Investing\\n "@en <http://800ceoread.com/products/big-wave-surfing-kenneth-j-thurber-english> .\n'
To unpack the first line from above a bit, the first part, b'_:node, tells us that this is an anonymous resource or blank node (one that doesn’t have a URI). The subsequent string of characters, e130f8cb43e689a9fee53a44337 is an identifier for the subject that has been assigned the blank node to disambiguate it from others. The next part, <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> specifies the namespace. Next, <http://schema.org/Offer> expresses that the relationship between the subject and object is that the subject is an offerFor the object, whose URI is <http://24h.pchome.com.tw/prod/DGBO6L-A72119703>.
Using rdflib
In Python, we can use the rdflib library (which you can install via pip) to build a graph structure from the product data we’ve downloaded:
from rdflib import ConjunctiveGraph
def make_graph_from_nquads(input_data):
g = ConjunctiveGraph(identifier="Products")
data = open(input_data, "rb")
g.parse(data, format="nquads")
return g
g = make_graph_from_nquads(os.path.join(base_folder, product_path))
The result is a ConjunctiveGraph, an aggregation of all the named graphs that can be extracted from our sample RDF document, whose length (len(g)) is equal to the number of nodes in the graph (in our case, 4983).
Now let’s take a look at what’s in our graph. We can traverse the graph using the graph.quads() method, which returns a generator. We can explore just first few like this:
for quad in g.quads():
print(quad)
print("")
(rdflib.term.BNode('N413e6a4d0e7b4e53adb8ba2d288468d9'), rdflib.term.URIRef('http://schema.org/Review/datePublished'), rdflib.term.Literal('Dec, 2007', lang='en-us'), <Graph identifier=http://alatest.com/reviews/fridge-freezer-reviews/gold-gi15nfrtb-15-built-in-ice-maker-with-25-lbs-capacity-storage-bin-50-lbs-daily-pro/po3-67344689,336/ (<class 'rdflib.graph.Graph'>)>)
(rdflib.term.BNode('Nf889a186374e4da8969f01e0834ba03a'), rdflib.term.URIRef('http://schema.org/Review/description'), rdflib.term.Literal('Overall, I am very pleased with this Netbook. The keyboard is just big enough to type comfortably on. I am able to stream Netflix, Hulu, and YouTube content with no problem. I was not able to watch over the air HD television with my Pinnacle HDTV USB...', lang='en-us'), <Graph identifier=http://alatest.com/reviews/netbook-mini-laptop/asus-epc1000he-blk005x/po3-180190577,354/ (<class 'rdflib.graph.Graph'>)>)
...
Let’s break down an example nquad, a small graph of an anonymous resource ('N6ac59173268e46b3b3307d84785d8416'), which expresses a keyword relationship ('http://schema.org/ImageObject/keywords') between the word ‘brainstorming’ and a stock photo:

(from Deposit Photos)
Suppose we wanted to search our graph to see if the photo has any other keywords? We can do so using the classes BNode and URIRef. A BNode is an anonymous or blank node, and a URIRef is a URI reference within the RDF graph.
from rdflib import BNode, URIRef
target_node = BNode('N6ac59173268e46b3b3307d84785d8416')
keyword_ref = URIRef('http://schema.org/ImageObject/keywords')
keywords = [
str(keyword) for bnode, linkage, keyword, product_uri
in g.quads((target_node, keyword_ref, None, None))
]
print(list(keywords))
['paperwork', 'brainstorm', 'laptop', 'stylish', 'people', 'technology',
'male', 'colleagues', 'partnership', 'documents', 'businessman',
'workplace', 'office', 'desk', 'showing', 'diary', 'adult', 'coworkers',
'well', 'shirt', 'strategy', 'working', 'together', 'team', 'corporate',
'caucasian', '20s', 'indoors', 'wireless', 'partners', 'young', '40s',
'computer', 'elegant', 'smart', 'explaining', 'teamwork', 'business',
'brainstorming', 'classy', 'dressed', 'pointing', 'communication',
'interaction', 'mature', 'sophisticated', 'meeting', 'man', 'bureau',
'staff']
Similarly, we might traverse through quads to find only those that have images associated with them:
image_ref = URIRef("http://schema.org/Product/image")
images = [
image for bnode, linkage, image, product_uri
in g.quads((None, image_ref, None, None))
]
Find the Products
As we can see, there are a lot of things in the graph that are related to products but aren’t actually products themselves, such as keywords, images, reviews, and offers (advertisements). So how can we find all of the products in the graph?
We can use the graph.subjects() method to traverse all the unique nodes of the graph to find ones that correspond to subjects, and we can further constrain the search by specifying the subset of subjects whose objects have the URIRef for products ("http://schema.org/Product").
from rdflib import URIRef
# get all the unique products
product_list = list(set(g.subjects(object=URIRef("http://schema.org/Product"))))
This leaves us with 216 unique products.
Now imagine that we’d like to index these products as documents in a document store like MongoDB or Elasticsearch, which would enable search in the context of (for instance) an application.
To do this, we’ll convert our graph into a dictionary representation, so that each product is represented as a key and the values correspond to the product details contained in the graph. First we’ll create a mapping between each of the possible product-related URIRefs and the field names to be used in Elasticsearch:
PRODUCT_FIELDS = {"name" : "http://schema.org/Product/name",
"image" : "http://schema.org/Product/image",
"url" : "http://schema.org/Product/url",
"desc" : "http://schema.org/Product/description",
"sku" : "http://schema.org/Product/sku",
"review" : "http://schema.org/Product/review",
"manu" : "http://schema.org/Product/manufacturer",
"reviews" : "http://schema.org/Product/reviews",
"prod_id" : "http://schema.org/Product/productID",
"mod_date": "http://schema.org/Product/dateModified",
"rel_date": "http://schema.org/Product/releaseDate",
"brand" : "http://schema.org/Product/brand",
"model" : "http://schema.org/Product/model",
"offers" : "http://schema.org/Product/offers",
"thumb" : "http://schema.org/Product/thumbnailUrl",
"logo" : "http://schema.org/Product/logo",
"rating" : "http://schema.org/Product/aggregateRating",
}
We’ll create a dictionary with keys for each unique product; each value will holds a dictionary with each of the possible product descriptors from the RDF graph.
Next, we’ll loop over each unique product id, and for each related quad in the graph (i.e. with a matching product id), and for each possible product URIRef, we’ll update the dictionary with the specific details of the linkage relationship for that product.
product_dict = dict()
# Seed each product node's value dict with the necessary fields
for product in product_list:
product_dict[str(product)] = {"name" : None,
"image" : None,
"url" : None,
"desc" : None,
"sku" : None,
"review" : None,
"manu" : None,
"reviews" : None,
"prod_id" : None,
"mod_date": None,
"rel_date": None,
"brand" : None,
"model" : None,
"offers" : None,
"thumb" : None,
"logo" : None,
"rating" : None}
# for each node in the graph that describes a product relationship
for bnode, linkage, detail, product_uri in g.quads( (product, None, None, None) ):
# for each mapping in our PRODUCT_FIELDS dictionary
for field_type, schema in PRODUCT_FIELDS.items():
# if the node's linkage matches the schema
if str(linkage) == schema:
# update the appropriate dict value for the key in our product_dict
product_dict[str(bnode)][field_type] = str(detail)
Now we can examine our (admittedly sparse) results!
from pprint import pprint
for key, val in product_dict.items():
print(key)
pprint(val)
break
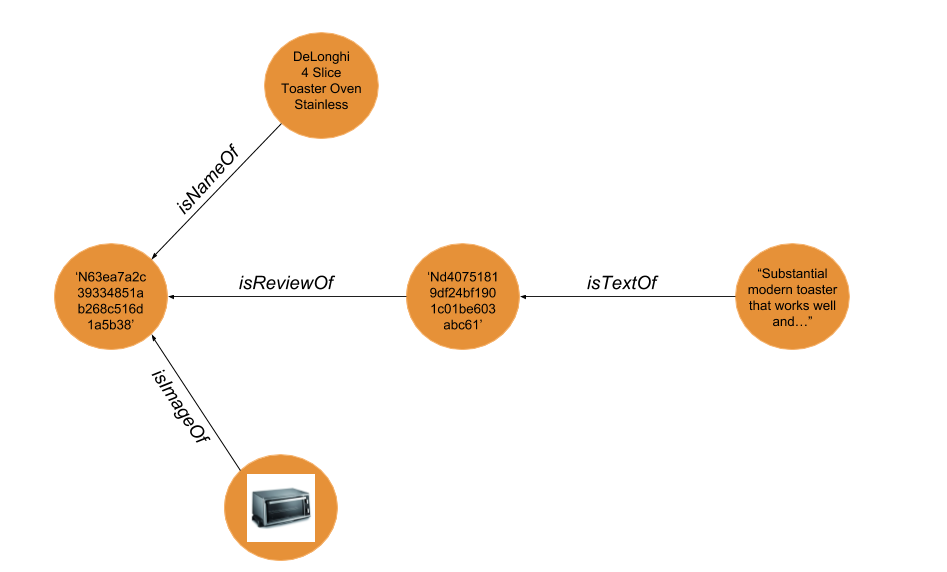
N63ea7a2c39334851ab268c516d1a5b38
{'brand': None,
'desc': None,
'image': 'http://ii.alatest.com/product/190x190/3/9/DeLonghi-4-10-D091549EFS-0.jpg',
'logo': None,
'manu': None,
'mod_date': None,
'model': None,
'name': 'DeLonghi 4 Slice Toaster Oven Stainless',
'offers': None,
'prod_id': None,
'rating': None,
'rel_date': None,
'review': 'Nd40751819df24bf1901c01be603abc61',
'reviews': None,
'sku': None,
'thumb': None,
'url': None}
Now let’s say we wanted to update our product dictionary to include data from the review nodes in the RDF graph. We can do so by find the nodes that correspond to the values in the review field in the dictionary values of each entry in the product_dict (e.g. 'Nd40751819df24bf1901c01be603abc61' above):
review_text = URIRef("http://schema.org/Review/description")
for product, val_dict in product_dict.items():
for bnode, linkage, detail, product_uri in g.quads( (None, review_text, None, None) ):
if val_dict['review'] == str(bnode):
val_dict['review'] = str(detail)
for key, val in product_dict.items():
print(key)
pprint(val)
break
N63ea7a2c39334851ab268c516d1a5b38
{'brand': None,
'desc': None,
'image': 'http://ii.alatest.com/product/190x190/3/9/DeLonghi-4-10-D091549EFS-0.jpg',
'logo': None,
'manu': None,
'mod_date': None,
'model': None,
'name': 'DeLonghi 4 Slice Toaster Oven Stainless',
'offers': None,
'prod_id': None,
'rating': None,
'rel_date': None,
'review': 'Substantial modern toaster that works well and is a great value. '
'We needed a 4 slicer since my husband has 2 waffles and I have 1 '
"our old toaster was only 2 slices so we couldn't have hot waffles "
"at the same time.Don't know what took me so long to get...",
'reviews': None,
'sku': None,
'thumb': None,
'url': None}
That’s all for now!
Next up maybe I’ll do a post on using the Python SPARQLWrapper to query RDF documents using the SPARQL query language. SPARQL can be used to express queries across diverse data sources, whether the data is stored natively as RDF or viewed as RDF via middleware. SPARQL contains capabilities for querying required and optional graph patterns along with their conjunctions and disjunctions. SPARQL also supports extensible value testing and constraining queries by source RDF graph. The results of SPARQL queries can be results sets or RDF graphs.