
It’s no secret that data scientists love scikit-learn, the Python machine learning library that provides a common interface to hundreds of machine learning models. But aside from the API, the useful feature extraction tools, and the sample datasets, two of the best things that scikit-learn has to offer are pipelines and (model-specific) pickles. Unfortunately, using pipelines and pickles together can be a bit tricky. In this post I’ll present a common problem that occurs when serializing and restoring scikit-learn pipelines, as well as a solution that I’ve found to be both practical and not hacky.
Pipelines
If you’re not familiar with scikit-learn Pipelines, they’re definitely worth a look (I particularly like Zac Stewart’s post on them). In essence, they (together with FeatureUnions) provide a method for sanely sequencing the stages of machine learning — from feature extraction to vectorization, normalization, dimensionality reduction, and modeling. Instead of a bunch of messy fit_transforms and fit_predicts, intermediate variables like “x_vectorized” or “y_encoded”, and steps requiring a human-in-the-loop to execute them in the proper sequence, Pipelines allow us to execute these steps in one fell swoop:
from sklearn.decomposition import PCA
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
steps = [
('scl', StandardScaler()),
('pca', PCA(n_components=2)),
('clf', DecisionTreeClassifier()
]
pipe = Pipeline(steps)
pipe.fit(X_train, y_train)
y_pred = pipe.predict(X_test)
Custom Estimators and Transformers
Even better, scikit-learn exposes two classes, BaseEstimator and TransformerMixin, which allow us to create our own custom steps for our pipelines. Let’s say we’ve made a special transformer for text data, TextNormalizer, that implements the transformer interface:
from sklearn.base import BaseEstimator, TransformerMixin
class TextNormalizer(BaseEstimator, TransformerMixin):
"""
Do a bunch of fancy, specialized text normalization steps,
like tokenization, part-of-speech tagging, lemmatization
and stopwords removal.
"""
...
def normalize(self, document):
# do the special stuff here
def fit(self, X, y=None):
return self
def transform(self, documents):
for document in documents:
yield self.normalize(document)
Now we can use our TextNormalizer in a pipeline! Since we’ll be using our custom text transformer to tokenize and tag our documents, we’ll specify that our TfidfVectorizer not do any tokenization, preprocessing, or lowercasing on our behalf (to do this we have to specify a dummy identity function to use as our tokenizer).
from sklearn.feature_extraction import TfidfVectorizer
...
def identity(words):
return words
steps = [
('norm', TextNormalizer()),
('vect', TfidfVectorizer(
tokenizer=identity,
preprocessor=None,
lowercase=False
)
),
('clfr', LogisticRegression()
]
pipe = Pipeline(steps)
pipe.fit(train_docs, train_labels)
predicted_labels = pipe.predict(test_docs)
Pickles
Let’s save that model! Python’s pickle library gives us a way to do this, and scikit-learn also has a specialized version of pickle called joblib that offers some specialization for serializing fitted scikit-learn estimators and transformers.
If we want to serialize the first model from this post (the one that does scaling, then dimensionality reduction, and finally classification using a decision tree), we do it like this:
from sklearn.externals import joblib
...
pipe.fit(X_train, y_train)
joblib.dump(pipe, 'scaled_tree_clf.pkl')
Then we can load the fitted model like this:
fitted_model = joblib.load('scaled_tree_clf.pkl')
Can’t we pickle and load our custom text classification pipeline in the exact same way?
Well, it depends…
If we try to load the serialized model in the same file in which the TextNormalizer has been defined, no problem:

But what if we have one library for testing/building models, and a separate application for serving predictions? In this case, you might encounter the following error:
AttributeError: module '__main__' has no attribute 'TextNormalizer'
or
AttributeError: module '__main__' has no attribute 'identity'
What happened??
Leaky Pipes
The problem is that we’ve defined our TextNormalizer class and identity function in one project, build_library, and our serve_library doesn’t know how to interpret those portions of the pickled pipeline when it tries to load the model.

The problem seems to manifest frequently on blogs and other sites like StackOverflow.
- Python: pickling and dealing with “AttributeError: ‘module’ object has no attribute ‘Thing’”
- Pickle Tfidfvectorizer along with a custom tokenizer
- AttributeError: module ‘main’ has no attribute ‘ItemSelector’
- Pickle serialization: module ‘main’ has no attribute ‘tokenize’
- Saving an sklearn
FunctionTransformerwith the function it wraps - Why does my Flask app work when executing using
python app.pybut not when usingheroku local weborflask run?
Many of the suggestions are to manually associate the custom class with the main module by doing:
if __name__ == "__main__":
normalizer = TextNormalizer()
TextNormalizer.__module__ = "model_maker"
normalizer.save("normalizer.pkl")
However, this felt like a less than satisfying answer.
Better Plumbing
My eventual solution was instead inspired by Matthew Plourde’s response to the question, How to save a custom transformer in sklearn?…
sklearn.preprocessing.StandardScalerworks because the class definition is available in thesklearnpackage installation, whichjoblibwill look up when you load the pickle. You’ll have to make yourCustomTransformerclass available in the new session, either by re-defining or importing it.pickleandjoblibwork the same way in this regard. Import information is stored with the pickled object, which is why you can screw things up when you unpickle an object made with a different version of a module than the one that’s currently installed.
I like his response because it helps us understand the underlying issue, which is that when you serialize an object with pickle or joblib, those libraries don’t only serialize the object, they store information about how to import the libraries and modules necessary for interpreting the object. Thus the solution is to make TextNormalizer and identity things that can, during the training phase, be imported by the build_library’s model_maker module, and later be imported from build_library by the serve_library:
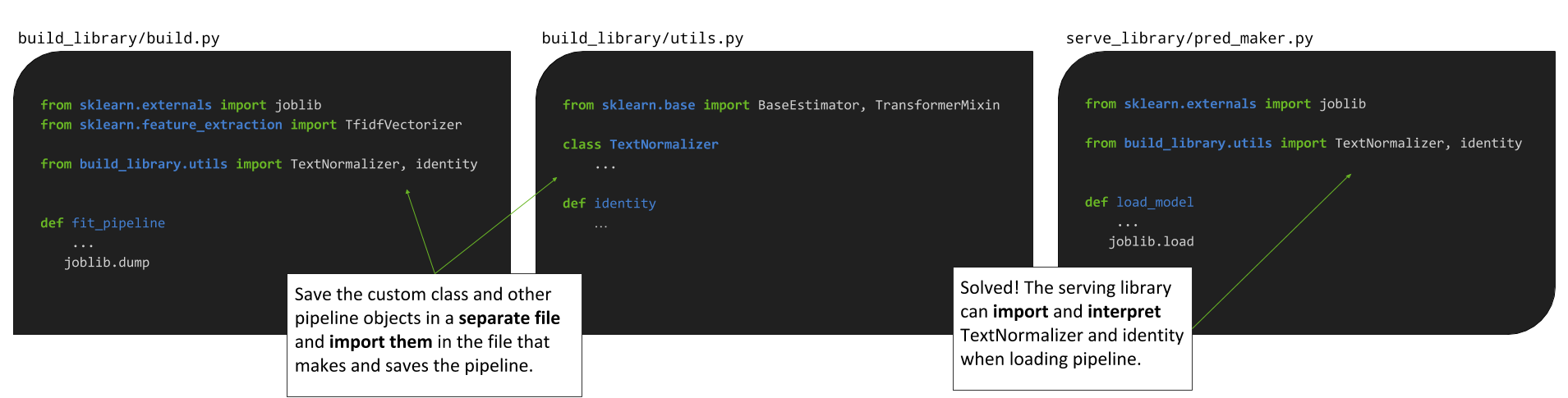
Note that this requires build_library be importable by serve_library; if build_library is a local/custom library and not pip install-able via PyPI, you can do either of the following:
- Add a
setup.pyfile to the top level directory ofbuild_libraryand usepip install -e .to install it in editable mode (which will put it in your PYTHONPATH). - Add a
setup.pyfile to the top level directory ofbuild_library, push to GitHub, and install viapip install -e git+ssh://git@github.com/yourorg/build_library.git